
This article is about the Domain Name System (DNS) and explains how the “Internet’s telephone book” works. Alongside the fundamental details of name resolution on the Internet, we also look at special topics like administering DNS records in dynamic environments and debugging DNS setups during operation. We look at it within the technical framework of Univention Corporate Server, because it contains not only a dyed-in-the-wool DNS server, but also diverse tools to make managing DNS records significantly easier.
DNS: A basic introduction
The Domain Name System, DNS for short, is an absolutely elementary component of the Internet. While many users and most admins have some idea of the terms “DNS server” or “name server”, the actual structure of the DNS system and its basic functionality is often unclear. Therefore, it is not a bad idea to look at the central aspects of the topic DNS, before looking as specific aspects of DNS in detail.
Numbers and figures
The phenomenon given the simple name “the Internet” is actually a global network of very many individual computers. Naturally, direct connections do not exist from each computer to every other computer. Instead, the computers comprising the Internet are partitioned into individual network segments. Within their network segments, the systems communicate directly with one another.
If a server from one segment wants to connect to a server from a different segment, it must use a router. But how does a server know how to reach another local server, or another server in a different segment of the network?
Here is where IP addresses come into play. An IP address is a sequence of numbers in 32 bits (for IPv4) or 128 bits (for IPv6) “IP” stands for “Internet Protocol”, which highlights this principle’s general validity. The IP address of the computer containing this blog, for example, is 217.160.0.58 (IPv4) and 2001:8d8:100f:f000::219 (IPv6) (see Fig. 1).

Fig.1: Host names normally point to an A record for IPv4 and/or an AAAA record for IPv6.
You can see that when a reader wants to access this blog via its IP address, they need to remember a complicated sequence of numbers. This is difficult for IPv4, but for IPv6 it is practically impossible – and this IPv6 address is not as complicated as it theoretically could be! Just imagine that you had to remember all the sequences of numbers just for the websites one uses regularly. It’s impossible!
The founding fathers of the Internet already realized that this would be a problem. They thought up a system which translated the complicated IP addresses into understandable texts (“hosts” or “host names”). For example, the IP addresses named above translate to blog.univention.de. And this can be remembered much easier than the actual IP addresses.
However, this system brings up a new question: how does the web browser know that it needs the server with IP address 217.160.0.58 when the user types https://blog.univention.de/ into the address bar? This is where the Domain Name System servers, DNS servers for short, come into play, because they function like a sort of telephone book and know which IP addresses belong to which names. It works the other way too, of course: individual IP addresses can have names defined in text form.

Relief for admins: Automatic processing of DNS records – and much more. Discover the possibilities of Univention Corporate Server with the free Core Edition!
How DNS became what it is today
Before we go into the details of DNS, it is worth having a little excursion into its history. DNS is not a new invention, but is one of the oldest principles of the Internet. It goes back to the American Paul Mockapetris, and 1983. It came about from necessity: the predecessor of what is now the “Internet” was a network purely for research called ARPANET. This grew rapidly during the 70s.
The idea of combining IP addresses with host names which could be remembered better already existed before the DNS system. One configured the host record statically on the computers with a file called HOSTS (or HOSTS.TXT). This required, however, that there was a central instance which could maintain this file because it knew all the computers and their IP addresses.
ARPANET, however, grew so quickly in the 70s that this was no longer possible in practice. Thus, Mockapetris came up with the basis of DNS and wrote them in RFC 882 and 883, which were later replaced by 1034 and 1035. What is particularly interesting is that DNS has not fundamentally changed in all the years since. Over the years, new functions have been added all the time, but the basic principles of the idea are still the same as nearly 40 years ago. Indeed, almost all updates to DNS over the years have been mainly to make the administration and use of name servers easier. Other improvements have been made to security. The possibility of exchanging DNS records between servers using IXFR commands was not provided for when DNS was started. Digital signatures for DNS records (DNSSEC) which are designed to stop misuse was also not important in 1983. Today both functions are standard and enjoy great popularity.
Two types of servers
Without name servers, the Internet would not really be usable anymore. It is obvious that a single name server cannot answer all the requests for the whole Internet. The load would be far too much for an individual server to handle. For this reason, the creators of the DNS system working alongside Paul Mockapetris came up with a mechanism which spreads the load out over as many servers as possible.
The schema designates individual DNS servers to be responsible for particular domains or addresses, while other DNS servers are responsible for other domains and IP addresses. What is important is that admins operating DNS servers differentiate between two types of DNS server.
- Recursive DNS servers (often referred to as “rDNS” or “resolving servers”) generally find out the IP addresses behind particular names – so a web browser wanting to know the IP address of blog.univention.de sends its query to a recursive DNS server.
- Authoritative DNS servers contain the canonical DNS records for individual domains or IP addresses. They are, therefore, the implicit contact point for recursive DNS servers as the last step in their queries.
Authoritative DNS servers may also act as recursive DNS servers for local clients but they do not have to. The DNS servers established on the market can also be divided into two types: those on which a single program is responsible for both recursive and authoritative DNS (e.g. Bind) and those which have separate components for these two tasks (e.g. PowerDNS).
By the way, in everyday administration, both recursive and authoritative name servers are generally designed with redundancy. This means that one client generally knows several recursive name servers so that it can still make queries even when one of those servers is not working.
Most domain registries provide at least two DNS servers per domain to resolve the domain’s records. There are no limits here in practice: in Linux, almost any amount of DNS servers can be configured and the number of authoritative DNS servers per domain is also unlimited.
The anatomy of a DNS query
As the explanation above shows, the domain univention.de has to have an authoritative DNS server which knows which IP address belongs to blog.univention.de. But how does a client which wants to access this website know which DNS server is responsible for the domain univention.de? This can be best understood by looking the the anatomy of a DNS query in detail. Because this shows that several DNS servers are involved with answering a query. The authoritative DNS server system is split into three levels:
Fig. 2: The root servers are the central instance of the DNS system, and the first point of contact for clients wanting to resolve host names.
- The first level are the root servers (Fig. 2). Each DNS server on the Internet which is involved in resolving public host names has a statically configured list of the existing root servers. However, the client does not find out anything about the responsibility for specific domains from the root servers. They contain only “root zone” information, that is which name servers are responsible for specific top-level domains (“TLD”). The top-level domains are identified by the last part of a host name, such as .de, .com or .info.
- When the client has discovered which name server is responsible for the top-level domain, it turns to this server directly and asks which authoritative name server is responsible for a specific domain. When the client knows the authoritative server responsible for a domain, it asks it for the IP address corresponding to the host name. The DNS query is then successfully completed.
Fig 3: The root servers manage the root zone of the overall Internet. They have a list of which name servers are responsible for which top-level domains (such as .com here).
The TLD servers are generally run by the domain registries of the countries involved. In Germany, for example, DeNIC runs .de. Thus before your web browser can actually open a website, behind the scenes many DNS queries are sent to different servers in a fraction of a second.
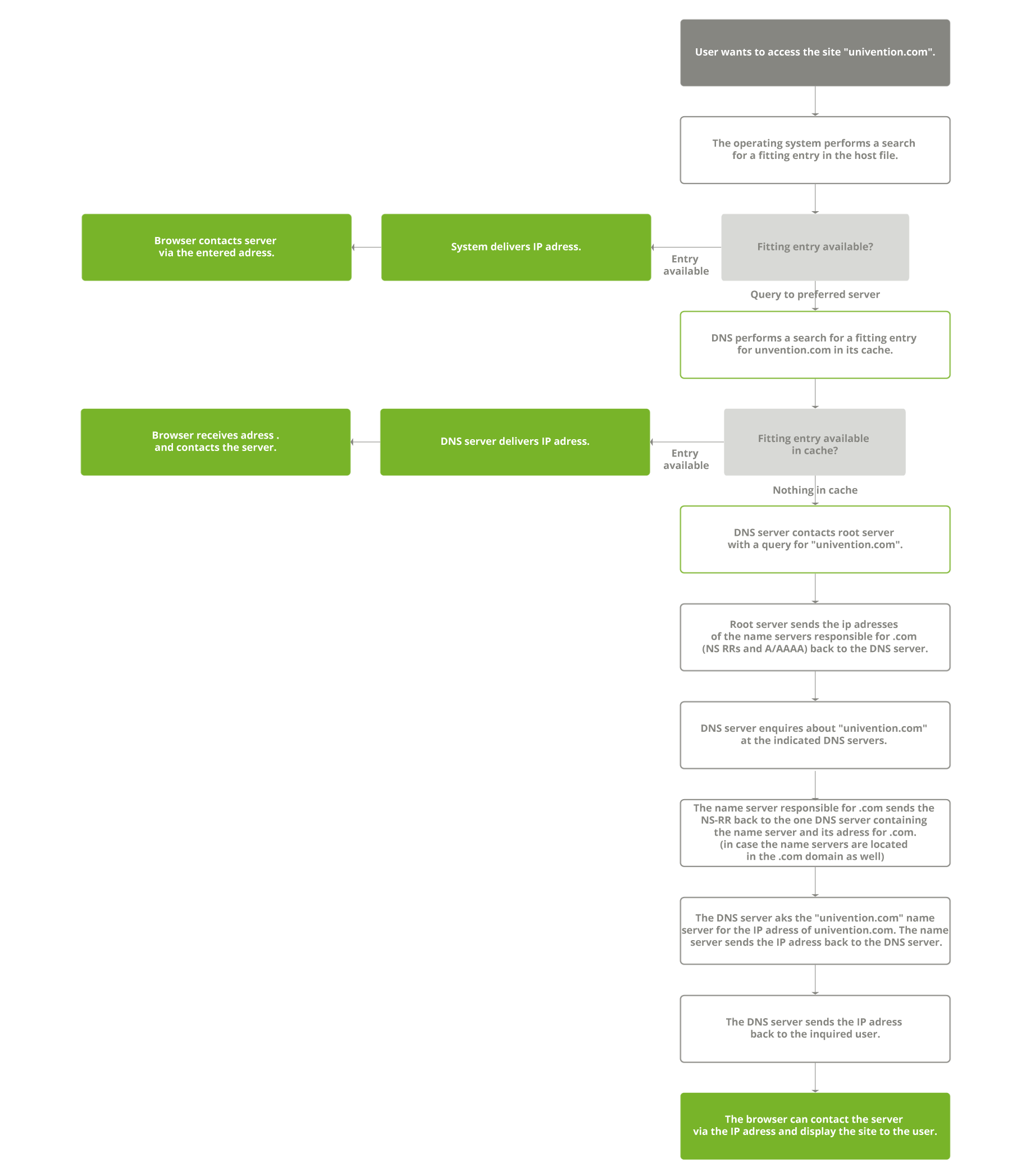
A client wanting to resolve a host name into an IP address has to complete a number of steps to get the answer
DNS use cases
The DNS functionality described covers the standard example in everyday IT, in which a client wants to communicate with a particular server via its host name. In practice, however, there are many further situations in which DNS is used – and in the future, the number of occasions will grow still further. Some classic use cases at the current time are:
• resolving host names from the World Wide Web in web browsers
• delivering emails within domains and sub-domains
• dynamically locating particular services (Kerberos, LDAP…) in distributed environments or within modern, container-based applications
• resolving host names in local environments for internal use, for example within a company under a pseudo top-level domain like .internal
• dynamically locating particular services or devices in environments in which protocols such as Bonjour or UPnP are used
• transport encoding for connections which are always based on the host name invoked, and which return an error when the host name and the certificate name differ
Various service providers have also started using the DNS protocol to implement global solutions like Content Delivery Networks (CDN) or geographical routing. Here, when a client sends a query to a DNS server, it returns values which are near to the client, geographically. Thus, CDNs can, for example, arrange that clients in Europe get their content from European computer centers and clients in Asia from Asian computer centers.
Recursive name servers in practice
Recursive and authoritative name servers place considerably different demands on the admins who operate them, with recursive name servers being significantly less laborious to administer. The steps needed to set up a recursive name server are always the same, regardless of the software used:
- Firstly, the admins install the name server software onto several systems, making sure that they use the correct IP addresses and that they are accessible externally. It is also necessary to open at least port 53 for the UDP protocol in any firewall.
- Admins who run their name servers on one of the established Linux distributions or under Windows generally receive the necessary configuration for recursive DNS alongside the name servers themselves, from the provider. It is only important that the records for the root server are correct.
- Alternatively, most DNS server programs can also be configured so that they do not directly communicate with the root servers, but rather forward incoming queries from clients to other recursive name servers (DNS request forwarding). If this is required, the admins configure their name server with the the IP address of the server to which the requests should be forwarded.
- It is best to limit access to the recursive DNS servers. Only few companies will want to operate a public name server for name resolution so that anyone in the Internet can use it. Depending on the software used, these limits are implemented in different ways. Almost all DNS server programs have the option to restrict their answers to queries coming from specific IP ranges. Firewalls provide another valid option.
Once the admins have worked their way through this list, they normally have one or two local DNS servers available for recursive DNS. Their IP addresses can then be registered on the client systems which can then contact them.
Authoritative name servers in practice
Setting up an authoritative DNS server is significantly more complicated. There are more things to keep in mind, which we will explore in this chapter in more detail. There are a number of terms used here, which not all admins will be familiar with, or which may have more than one possible meaning. For this reason, we will start with an explanation of these terms.
Zones and records
Anyone who has anything to do with setting up a DNS server will regularly come across the term “zone”. They sound complicated but are actually very simple: the term “zone” in the context of DNS is used to describe the configuration of a name server for a specific domain. The term originates in the history of BIND, the first and for a long time the most widespread DNS sever system in the history of the Internet. It saves the configuration of individual domains in “zone files”.
- A zone is characterized by a range of details. Every zone must have an SOA record. The acronym stands for “Start of Authority” and defines which domains the zone is valid for, the current serial number and the “TTL” (time to live) of individual records (these terms will be dealt with later in this article).
- The second regularly used term is “record“. Here you need to know that the zones for domains in DNS servers generally have a range of records of different types, in addition to the SOA record. The information, for example, that blog.univention.de resolves to the IP address
217.160.0.58is an A record. As IPv6 builds on IPv4, and has four times as large an address space, IPv6 records in zone files are called AAAA records. - A zone does not have to have any A records or AAAA records. It does, however, have to have at least one NS record. “NS” stands for “name server”; an NS record is needed in each zone on each authoritative name server, at least one which points to itself. Otherwise, the DNS server will not consider itself responsible for the domain, and it will ignore queries. NS records are useful when transferring zones between servers. If you have an primary authoritative name server operating and want to install a secondary authoritative name server, save the NS records for both systems on the primary server. When the secondary name server is correctly configured, the primary name server will synchronize the contents of the zone file with the secondary server automatically.
- There are further types of record which are relevant in everyday use. MX records define “mail exchangers” for domains. This means they set out where a domain’s emails should go. Like NS records, there can be many of them. While NS records and A or AAAA records only define host names and IP addresses, in MX records, admins set up a sequence of mail servers to be tried one after the other. We should not forget PTR records, TXT records and SRV records.
- PTR records are the counterpart to A or AAAA records, but for IP addresses. The process of resolving a domain name to an IP address is called “forward DNS lookup”, or simply “DNS lookup”. A query of PTR records is generally called “reverse DNS lookup”. Admins use a PTR record to set out the host names an IP address should be associated to.
- TXT records allow arbitrary texts to be stored in the DNS system. This is useful, for example, to prove that one actually has control over a particular domain.
- SRV records are used in modern dynamic environments for locating specific services. If a Kerberos client in an Active Directory Network wants to know where it can reach the Active Directory Server, it looks in the relevant SRV record for the relevant domain.
No insurmountable hurdles
The good news it: if you understand the essential anatomy of a zone in a DNS system, you do not have to fear any large problems when operating an authoritative DNS server. The following steps need to be taken:
- Firstly, admins install the name server software wanted and sort out the basic settings. In the configuration, they define which clients have access, from which IP addresses the DNS server accepts inbound queries, and for which zones and name servers it is responsible.
- Then the zones are set out in the name server for the domains. Each zone needs an SOA record and an NS record. It is recommended, however, to also maintain A records, AAAA records and MX records carefully from the start. This also holds for subdomains: blog.univention.de could have somewhat different MX records to univention.de. An A or AAAA record can also point to several IP addresses. When queried, the relevant name server will then randomly chose one of these IP addresses to return (this is called round-robin DNS).
- Then further authoritative name servers are configured which act as secondary servers. If the admins have correctly configured the system, the primary name server will convey the configuration of a zone to the secondary servers automatically using AXFR (Asynchronous Xfer Full Range) – or IXFR (Incremental Zone Transfer).
In practice: debugging recursive DNS
Now that we have explained the basics of how DNS works, we would like to tackle the question of what problems confront admins in everyday use and how they can respond properly. Problems both large and small are caused time and again by both incorrectly configured authoritative name servers and unregistered or poorly-configured recursive name servers. But do not panic: if you have the right tools, standard errors can be solved very quickly.
This chapter deals with problems in recursive DNS. These are particularly treacherous as complaints from inexperienced users that “the Internet isn’t working” can often be traced back to DNS problems. For such cases, therefore, this is the first thing to check.
There is a trick to this: if the user opens a console on Linux or cmd.exe on windows, the command ping 8.8.8.8 reveals whether the basic Internet connection is working. 8.8.8.8 is Google’s central public name server which can be counted on to react to ICMP queries (i.e. ping). If there is an error message here, then the problem is not at the level of DNS.
On the other hand, if the ping command returns echo replies, the next step is to use ping univention.de to find out if the name resolution works. If this returns an error message such as Host not found, then something fundamental is wrong (Fig. 4).

Fig.4: If the ping command works with an IP address but not with a host name, then something is wrong with the DNS setup.
Problem: no name server registered
When no name server as been set up for a system, name resolution will fail for every program. The problem is mainly encountered by client computers in both the private and professional sphere. When it is not possible to open websites on a system, it is always a good idea to check the current name server records.
For Linux systems, the user can always find these in /etc/resolv.conf. If there are no records in this file of the form “name server IP address”, then DNS records cannot be resolved. Windows clients show the DNS configuration in the TCP/IP properties of the relevant network adapter.
There are many reason for clients having no name servers configured – assuming, of course, that the client’s Internet connection works at all. The most mundane option is that the system has a statically configured TCP/IP stack, and the admin who set it up forgot to add the name servers. Then the necessary name servers need to be added to the TCP/IP configuration by hand.
It is now much more common, however, to configure the client systems dynamically via DHCP. And DHCP contains a separate field for name servers, so that it configures them automatically. A look at the configuration of the DHCP server is enough to see if this also assigns name servers.
Find out more about DHCP (Dynamic Host Configuration Protocol) and its interaction with DNS!
Problem: DNS server cannot be reached
If this is the case, the admins have further debugging to do. This is because it is probable that the client cannot reach the name server configured. Thus, the admins must then check the network connection between the client and name server, ideally directly from the system. Linux has a tool called dig, which helps to uncover DNS server problems. It is a DNS client itself. If /etc/resolv.conf contains, for example, the line nameserver 192.168.0.1, the command dig univention.de @192.168.0.1 queries the entry for univention.de at this name server. The ANSWER SECTION is important in the response, which should reveal the relevant A record. If network problems are the cause of the error, the tool exits with an appropriate error message.
Problem: recursive DNS is incorrectly configured
Should there be no such error message, things get interesting – for example if dig can reach the name server but it returns an empty reply. Then the problem is probably an incorrectly configured recursive DNS server, which, for instance, cannot reach its DNS forwarder. One cannot really set out a probably cause for all such cases though. Incorrectly configured name servers force the admins to consider the details of their configuration and their log files.
It may be possible to diagnose the problem using dig: if the dig command above gives an error message when the local DNS server is the target but returns the correct record for the DNS server 8.8.8.8, then the problem is the recursive server. This is because when the admin explicitly specifies a name server, dig ignores the contents of /etc/resolv.conf.
Problem: DNS server answers, but delivers what seem to be incorrect values
The final problem in the example is one of the most awkward problems in the context of DNS because, in the worst case scenario, end users have no remedy other than to wait. There are certainly cases in which certain host names actually do resolve to IP addresses, but these are not able to be reached. This happens often when the admins of authoritative name server responsible for a domain change its configuration.
It is important to know that DNS has a built-in expiry date for DNS records, called time to live (abbreviated as TTL). These serve primarily to improve performance: when a recursive name server knows that the TTL record of the host name blog.univention.de is valid for 24 hours, it only needs to do go through the motions of querying the root server, the TLD server and the authoritative name server once every 24 hours. The rest of the time, it saves the result in its cache. When a client requests the IP of the host name once more, it answers with the value saved in the cache. This lowers the load on the DNS system overall and leads to quicker answers for clients.
The disadvantage is that should the authoritative DNS zone of a domain change, the admins can only assume that all clients are actually using the zone as altered when the TTL has expired. And de facto, they cannot even assume that, as some operating systems add their own local DNS caching too.
Changes can only be made in such situations conditionally. When a recursive name server is under ones own control, restarting the service will normally empty the cache. However, this will only help when the recursive DNS server actually undertakes the resolution itself and does not use a forwarding server. Operating system DNS caches are also a factor, as described above. The documentation of the system used will generally include information about how the DNS cache can be emptied.
In addition: the TTL valid for an individual DNS record can be found using dig. It is the number which is directly behind the host name queried in the ANSWER SECTION of a query (Fig. 5).

Fig. 5: The record directly after the host name in the ANSWER SECTION of a query with dig describes the TTL.
In practice: debugging authoritative DNS
Problems with authoritative DNS are generally significantly more complex than those with recursive DNS. This is because there are a number of factors which determine the success or failure of DNS queries here.
Problem: primary and secondary name servers are not the same
A problem which comes up a lot is, for instance, that the contents of a primary and secondary name server differ. Both servers return valid answers, but they are different. This happens regularly when the synchronization of records between the name servers does not work. The first place the admins should look is the servers’ log data which will generally contain corresponding error messages.
Problem: there are records in the zones, but they cannot be called up
Similarly, a common problem is that there seem to be records in the DNS zones, but they do not actually make certain host names resolvable. This has, above all, to do with the way in which DNS records are kept in zones – less experienced admins often make mistakes here with the syntax. If a record in a DNS zone is actually there but not available, and if a possible difference between the primary and secondary server has been ruled out, then there is nothing for it but to study the documentation of the server software so as to tackle the problem.
Problem: incorrect name server listed
It is not uncommon that the wrong name server is listed for a domain on the TLD servers. In principle, admins enter the name server when they register a domain, which needs to have already had its basic configuration carried out. Most domain registries will otherwise refuse the registration straight away. Should zones be transferred from one authoritative DNS server to another, the name server registration at the registry for this domain also needs to be changed. It is not enough to only change the NS records on the name servers themselves. As otherwise, recursive name servers will be forwarded to the old name servers by the TLD servers.
DNS in UCS
The final chapter of this article is dedicated to the question of how UCS deals with the topic DNS, and what functionality is available out of the box. As a basic principle, UCS treats DNS as what it is: an elementary component of networks. Thus it tries to process the majority of the DNS configuration automatically, without bothering the administrator.
In plain language, this means that DNS servers always run alongside every UCS domain controller and any secondary controller (these are called directory nodes from UCS 5.0 on). The principle is that they get their configuration from OpenLDAP, the central directory service, which also belongs to UCS. When UCS is used as a domain controller, DNS plays a particularly large role: as already mentioned, it is then necessary to have correct DNS records for specific servers and services, as otherwise, for instance, the authentication of users and single sign on will no longer work. Reverse lookups, i.e. resolving PTR records has to function. So after the admins have configured it, UCS takes care of these records itself. (Fig. 6)
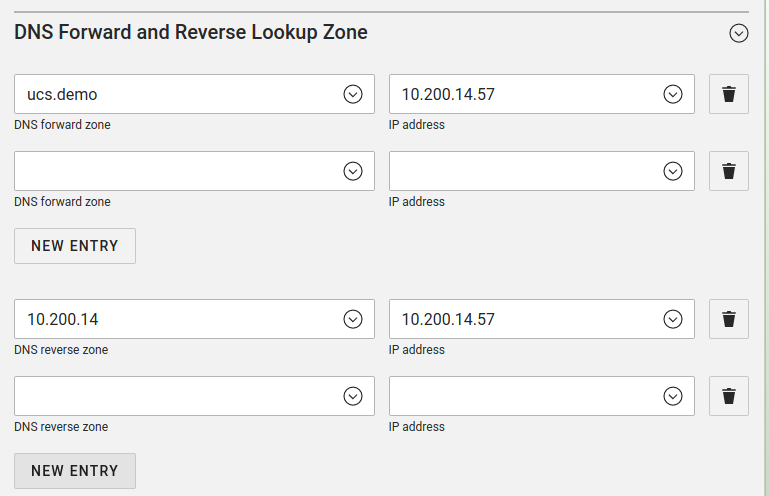
Fig. 6: Univention UCS manages its own DNS records itself and points to other records on external name servers – or resolves them itself via the root servers.
In domains compatible with Active Directory, UCS also supports the DNS components of Samba 4, which can then be used as the basis for name servers instead of OpenLDAP. In such setups, our own tool makes sure that the DNS records from Samba get to OpenLDAP and vice versa. UCS also operates a DHCP server itself (which requires some configuration, whereas DNS is largely automatically configured). Because of this, in the standard configuration at least, it is ensured that clients know the correct DNS server.
On the other hand, UCS is not designed to be used as a general recursive or authoritative name server for specific domains. Ideally, matching name servers are set up to complement UCS before its installation, to be used as “forwarding servers” in UCS. Then when clients make DNS queries which the name server integrated in UCS cannot answer, it forwards them on the externally configured server. Alternatively, UCS can be configured so that it takes over the connections to the DNS root server itself.
The admins do not have to operate external DNS servers themselves, by the way. For example, one could use the name server which are generally offered by the domain registry. These can generally be managed via convenient GUIs (Fig. 7).
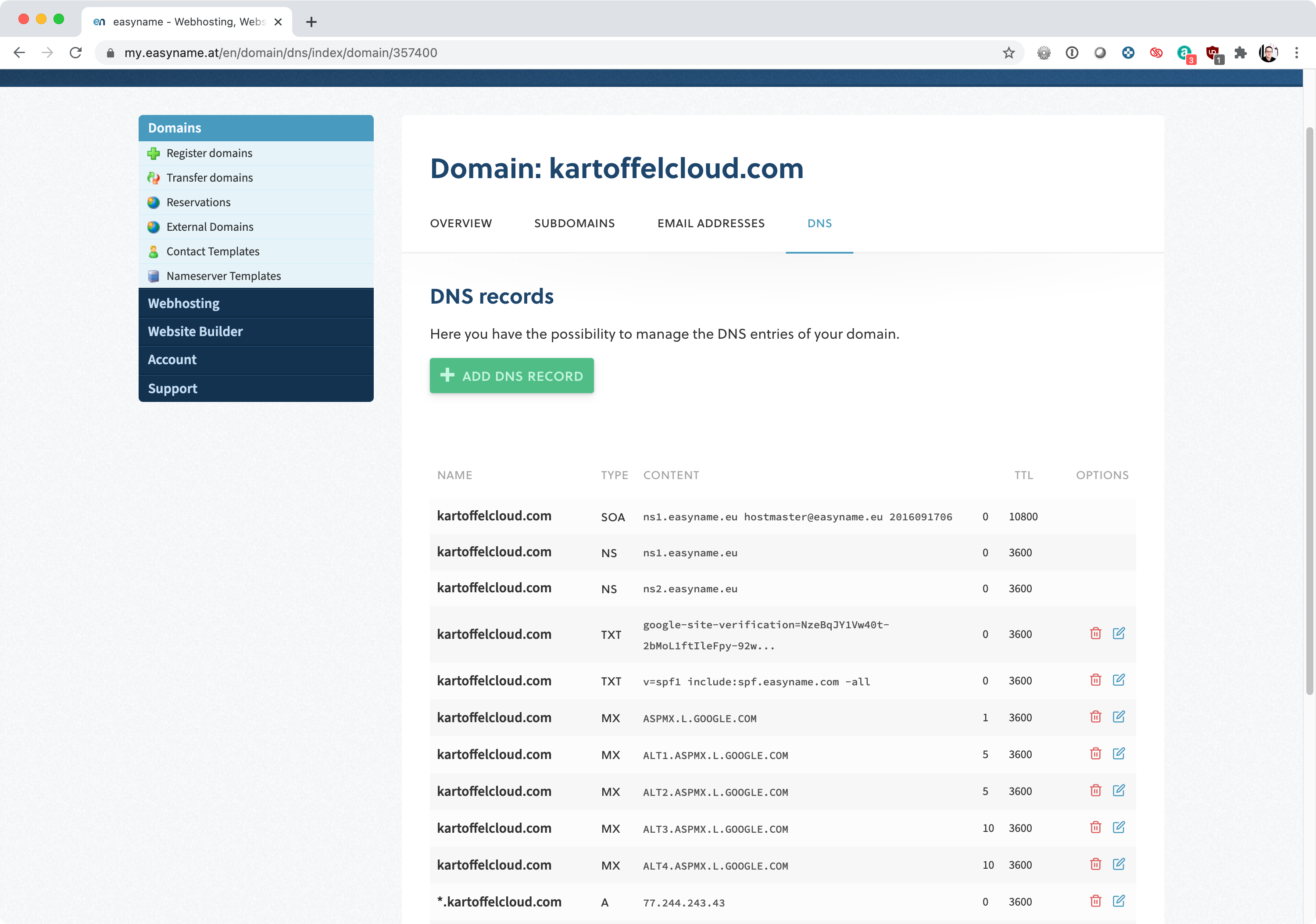
Fig. 7: Most domain registries offer external name servers – they are easy to configure and convenient to use.
We hope that you enjoyed this introduction to DNS and found it somewhat helpful. Got any questions, suggestions or additions? We’re looking forward to our comments!


Comments
Charles
The longer that i read about UCS as it has been updated the better it seems to be getting.
I have been working on matrix.org for a little over a year and testing it on different OS platforms and have yet to try it with yours but i think it’ll make things a lot easier to deploy especially now with more workers trying to work from home and the security nightmare of managing so many systems in constantly changing network environments.