
The majority of the environments in which UCS is employed include anywhere from a couple of dozen users up to several thousand – sizes which can be directly implemented with the standard configuration of UCS. In the systems operated by the education authorities we see a leap to between 10,000 and 100,000 users – in this case, the UCS@school concepts allow functioning scaling.
Even including groups, hosts, and other LDAP infrastructure objects in the calculations, these environments rarely exceed 200,000 objects. But what happens when an environment with more than 30,000,000 objects needs to be administrated in LDAP?
The framework conditions
In 2014, a project was launched where Univention found itself faced with precisely this question. It involved the administration of 30,000,000 accounts (comparable with the “simple authentication account” in Univention Directory Manager), complemented with a whole range of different parameters. These accounts serve as a user directory for mail and groupware services based on Dovecot and Open-Xchange. It comes as no surprise that environments of this size are also subject to considerable loads: Several million logins and thousands upon thousands of changes need to be processed every hour.
The question before anything else – Is it even possible?
Even before the project really got under way, the question on everybody’s lips was: Is that possible with UCS? Is that even possible with OpenLDAP?
At the time, we addressed the question with UCS 3.2; UCS 4.0 had yet to be released. The first tests revealed: The necessary performance is achievable, but only barely with UCS 3.2. The bottleneck back then was the “BDB” backend of OpenLDAP. The dubious aspects were not only that the standard configuration in the product was insufficient for the scope, but also that not all the values recorded when measurements were taken on a standard server system were particularly compelling.
When UCS 3.0 was released back in 2011, BDB was the standard backend of the OpenLDAP version included. However, intensive work on its successor, “MDB” (Memory-Mapped Database), was already under way in the OpenLDAP project. During the performance tests in 2014, the MDB backend was determined to be stable. As a result, testing this backend also became a priority.
MDB vs BDB – an unexpected distinction
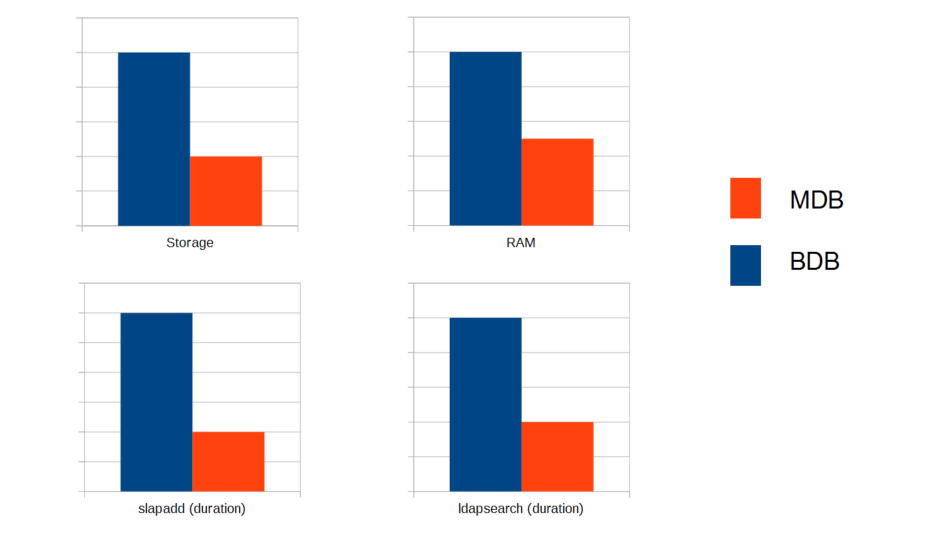
The difference in performance between MDB and BDB proved to be surprisingly evident. While MDB only consumed 30-50% of the RAM and hard drive space required by BDB, the response time for LDAP edits and requests was just 25-30%. As such, MDB is between three and four times quicker than BDB. All the tests were conducted with a database of 30 million objects (an LDIF of approx. 60 GB). The time measurement of LDAP searches was conducted with several thousand sequentially performed searches with LDAP filters stored in the database index. The CPU utilization at the same time was also very positive: Whereas BDB required an entire CPU core for the sequential performance of the LDAP searches, the increase in the utilization was barely noticeable with MDB. Short tests revealed that this behavior remained unchanged even when the number of objects exceeded 50 million, meaning further scaling in this project would still be possible with ease. Based on these clear advantages, the decision was taken to employ MDB for the project: A decision which also led to MDB’s becoming the default backend in UCS 4.0.
Hurdles encountered with MDB
As always when switching over to a new technology, there are some changes that need to be taken into consideration with MDB too. Whereas the somewhat laborious fine-tuning of database parameters as required by BDB in DB-CONFIG is no longer necessary, MDB offers a very decisive option in slapd.conf: “maxsize” (UCR: ldap/database/mdb/maxsize). The size specified here in bytes defines the upper limit for the size of the MDB database, i.e. the file /var/lib/univention-ldap/ldap/data.mdb in UCS. This value needs to be increased in large environments; In this specific project 250 GB was selected so as to allow for a considerable buffer. The important thing to remember when dealing with this file is that it is a “sparse” file. This format is also popular for “thin provisioning” in the virtualization environment and demonstrates slightly unusual behavior: While an “ls” on the file indicates the full maximum size (corresponding to “maxsize”), it only uses the space on the file system that it actually requires (e.g., in the output of “df”). However, not all tools are provided with this condition. For example, a simple “cp” results in a copy in the full “maxsize” size. The backup tool used should be able to come to terms with this for example. Another particularity of these files is the fact that the memory consumption never decreases – if data are deleted from the LDAP, the memory is only marked as “free” within the MDB file and not made available in the file system.
A serious difference in practice is the I/O utilization generated by MDB for changes. MDB offers the decisive advantage here that the database file is consistent in itself at any time. Put simply, a new version of an LDAP object or its attributes are first written to a free space in the file and then simply rerouted from the old to the new version via a link. At the same time, MDB generates a whole host of small writing operations, especially if a range of indices need to be updated for a change. The storage system therefore needs to be able to deal with a large number of IOPs (> 10,000 in this project). If several LDAP servers are mounted on one shared, network-based storage system, as is often the case in virtualized environments, this soon forms a bottleneck. This behavior can be lessened via configuration. However, as this increases the risk of data loss, it should not be employed in standard use. The most extensive of these options (“nosync”) can be practical for an initial data import via “slappadd” though – in our project, it was possible to realize the initialization of an individual MDB database in this way in under four hours.
In practice
First of all: The number of aspects to be taken into account when operating UCS in an environment of this size is surprisingly low. The entire management system, in other words also the management of the LDAP objects in the web interface, manages with this quantity of information directly. A prerequisite for this is scrutiny of the LDAP indices for the values required in practice and sufficient RAM on the LDAP servers so that there is no need to resort to the storage system for access to the indices. The RAM sizes for the project fluctuated between 32 and 96 GB.
An environment for a project of this size is naturally not only composed of a single LDAP server, but of dozens. The set-up and operation of this environment requires a higher number of manual interventions in order not to generate unnecessary long waiting times. Whereas integrating a new UCS LDAP server for a few thousand users takes an hour or two, initializing the LDAP server in the standard domain join manner with 30 million objects would literally take days.
When rolling out a new LDAP server, the UCS domain join is such that the new server creates an empty LDAP database locally, exports all objects from the UCS master with “ldapsearch” and then imports them locally with “ldapadd”. OpenLDAP serves a single, reading client (this corresponds to one process on the server) at around 1,000 LDAP objects/second – in this environment, the export still takes more than 8 hours. There are a number of reasons for this. The decisive aspect, however, is that the export of the LDAP from the UCS master via “ldapsearch” and the import of the LDAP objects via an “ldapadd” only generate one process each and thus do no scale over multiple CPU cores. Most of the times, this process only has to wait for the storage system.
In a standard configuration of UCS, the domain join fails due to a timeout. For this reason, alternative deployment methods were developed in the project which build on an existing MDB database (e.g., of an identically configured LDAP server), accept an LDIF, or avoid the timeouts by means of paged LDAP searches. Depending on the procedure, the deployment of a new server takes anywhere from under an hour up to several days.
Further fine-tuning is also required for some CRON jobs in UCS. For example, the daily back-up of the LDAP in an LDIF only remains active on selected servers, as the available disk space otherwise fills up very quickly.
What is not possible
One decisive factor for the success of this project is not directly linked to LDAP: The use of simple authentication accounts and project-specific LDAP objects derived from them. These accounts do not have any POSIX, Samba, or Kerberos attributes or group memberships. There are otherwise a whole host of limitations lurking here – to name but a few: both POSIX (uidNumber) and Samba (SID) employ numerical IDs with standard number ranges which are too small. In the presetting, all accounts would become members of the same standard group, which would already cause problems for some client systems with a couple of thousand users.
Summary
After the two fundamental decisions were taken – to use MDB as the backend for OpenLDAP and to manage project-specific objects in LDAP – the realization of a directory service with more than 30 million objects with UCS and OpenLDAP proved to be very possible. This technical component was soon no longer the focus of the project, which switched instead to the realization of the logic based on it for the maintenance of the accounts.


Comments
Jarbas Peixoto Junior
I searched for evidence that openldap supports a number of these entries, and this excellent article showed me that it is possible.
Thanks for sharing.